Using Google Cloud Vertex AI
Take-home activity! Do it if you are following along at home. It won't be covered during the hands-on lab.
Google Cloud now offers a series of AI platform services that are built on top of Vertex AI. These services are designed to help you build, deploy, and manage machine learning models.
To create embeddings, they offer several services to convert text, images, or both into embeddings. In our application, we will use the multimodal embedding model to search for books by a description of the cover image.
Create a Google Cloud account
The first step is to create a Google Cloud account. Use the following link to get started with free credits.
Sign Up for a Google Cloud Account
Create a new project
For the welcome screen, create a new project. You can name it whatever you like.
Make sure that you pick an active billing account.
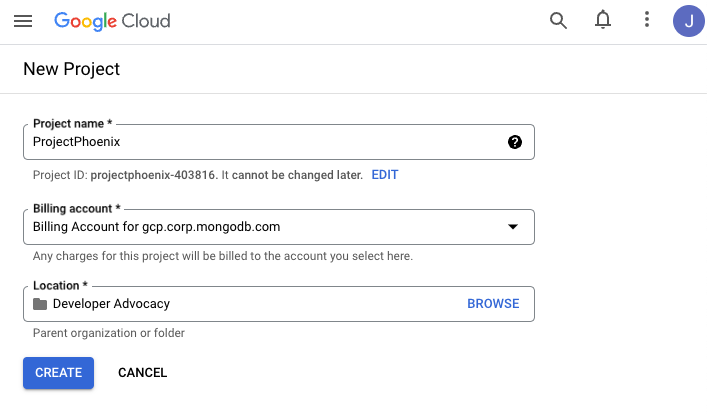
Once the fields are filled out, click the Create button.
Open Cloud Shell
Once your project is created, look for the Activate Cloud Shell button in the top right corner of the screen.

This will open up a terminal-like window in your browser. This is a fully functional terminal that is connected to a virtual machine in the cloud. You can use this terminal to run commands on your virtual machine.
Enable the AI Platform API
You will need to enable the AI Platform API for your project. You can do this by running the following command in your Cloud Shell.
gcloud services enable aiplatform.googleapis.com
Create an authentication file
To authenticate with the AI Platform API, you will need to create a file that contains your application credentials. You can do this by running the following command in your Cloud Shell.
gcloud auth application-default login
Follow the instructions in the terminal to authenticate with your Google Cloud account. Once you have authenticated, you will see a message similar to the following.
Credentials saved to file: [/tmp/tmp.n0HdRFDDv8/application_default_credentials.json]
Save the credentials file to your home directory.
mv /tmp/tmp.n0HdRFDDv8/application_default_credentials.json ~/credentials.json
Create embeddings for some text
Start by creating a request.json file. This file will contain the text that you want to convert into embeddings. Run the following command in the Cloud Shell to create this file.
echo '{
"instances": [
{
"text": "picture of a cat"
}
]
}' >> request.json
Now run the following curl command to get the embeddings for the text.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/multimodalembedding@001:predict"
Make sure to change the $PROJECT_ID variable to your project ID.
You will receive a response similar to:
{
"predictions": [
{
"textEmbedding": [
-0.00566103263,
0.0202014241,
-0.00677233562,
0.0180264488,
0.0265100803,
...
0.00116232142,
0.0134601779,
-0.00257002981
]
}
],
"deployedModelId": "5595742328217141248"
}
You will notice that the textEmbeddings fields contain an array of 1408 numbers. These are the embeddings for the text that you provided.
Create embeddings for the books
To create the embeddings for the books in your collection, run this curl command for each book. This process is somewhat time-consuming, so we've already created them for you.
You can find the 1408 dimensions vector in the embeddings field of the new books collection you imported.
Because we already have the vectors for the books, we can use them with Vector Search.
Querying with vectors
To query the data, Vector Search will need to calculate the distance between the query vector and the vectors of the documents in the collection.
To do so, you will need to vectorize your query. You can use the same function to vectorize your query, as well.
- 🚀 NodeJS/Express
- ☕️ Java Spring Boot
In the library application, we've created a function that will vectorize your query for you. You can find it in the server/embeddings/googleVertex.mjs file.
import aiplatform from '@google-cloud/aiplatform';
const project = process.env.PROJECT_ID;
const location = process.env.PROJECT_LOCATION;
const {PredictionServiceClient} = aiplatform.v1;
const {helpers} = aiplatform;
const predictionServiceClient = new PredictionServiceClient({
apiEndpoint: 'us-central1-aiplatform.googleapis.com'
});
const getTermEmbeddings = async (text) => {
const publisher = "google";
const model = 'multimodalembedding@001';
// Configure the parent resource
const endpoint = `projects/${project}/locations/${location}/publishers/${publisher}/models/${model}`;
const instance = { text };
const instanceValue = helpers.toValue(instance);
const instances = [instanceValue];
const request = {
endpoint,
instances
};
// Predict request
const [response] = await predictionServiceClient.predict(request);
const embeddings = response.predictions[0].structValue.fields.textEmbedding.listValue.values.map(e => e.numberValue);
return embeddings;
};
export default getTermEmbeddings;
Configuring the application
In your server/.env file, you'll find a few variables that you can use to configure the application.
The first one is EMBEDDINGS_SOURCE. It tells the application where to get the embeddings from. You can set it to googleVertex.
Then, set the EMBEDDING_KEY to your credentials.json file.
Finally, set the PROJECT_ID and PROJECT_LOCATION to the values for your project.
EMBEDDINGS_SOURCE=googleVertex
EMBEDDING_KEY="./credentials.json"
PROJECT_ID=projectphoenix-verteximage
PROJECT_LOCATION=us-central1
Your application now has a getTermEmbeddings function that will return the embeddings for a given text. You can see the details of this file in the server/src/embeddings/googleVertex.js file.
To run semantic queries in Java, the application also needs to generate embeddings for your query.
This is handled by the EmbeddingProvider interface.
For Google Vertex AI, the implementation is VertexEmbeddingProvider, which delegates the HTTP call to the Feign client:
@FeignClient(
name = "vertex-embeddings",
url = "${vertex.base-url}"
)
public interface VertexEmbeddingClient {
@PostMapping(
value = "/v1/projects/{projectId}/locations/us-central1/publishers/google/models/{model}:predict",
consumes = MediaType.APPLICATION_JSON_VALUE)
VertexEmbeddingResponse predict(
@RequestHeader("Authorization") String bearerToken,
@PathVariable("projectId") String projectId,
@PathVariable("model") String model,
@RequestBody VertexEmbeddingRequest request
);
}
Configuring the application
To use Google Vertex AI, adjust the following parameters in application.yml:
embeddings:
source: ${EMBEDDING_SOURCE}
vertex:
project-id: ${VERTEX_PROJECT_ID:yourProjectId}
api-key: ${VERTEX_KEY:yourKey}
The embeddings.source property is what selects the provider at runtime. If you set it to googleVertex, the Vertex implementation will be used. You can either edit these values in application.yml, or export them as environment variables:
export EMBEDDING_SOURCE=googleVertex
export VERTEX_PROJECT_ID=<YOUR_PROJECT_ID>
export VERTEX_KEY=<YOUR_KEY>
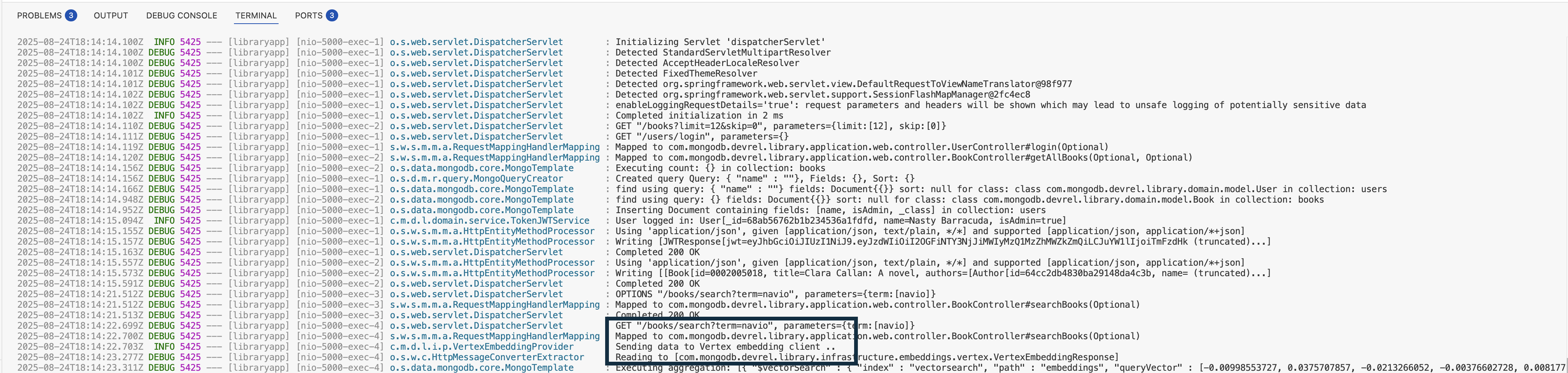
Running the application
Once the variables are set, start the application as usual:
mvn spring-boot:run
At the end, when the application starts, just make a call to searchBooks as
described in the step Add Semantic Search to Your Application
and you will see the application calling the Google Vertex implementation: