📘 什么是向量?
简单来说,向量就是一个数字列表。例如,长度为 3 的向量可以是 [1, 2, 3]。长度为 5 的向量可以是 [1, 2, 3, 4, 5]。长度为 100 的向量可以是 [1, 2, 3, 4, 5, ..., 100]。向量的长度是它包含的元素数量。
在 AI 中,��向量是数据的数学表示。
当谈到生成式 AI 时,你会听到向量和嵌入(Embedding)这两个术语。虽然它们不完全相同,但你会经常看到这两个术语互换使用。
从技术上讲,嵌入是由模型创建的向量。例如,一个模型可以将一个词转换为一个向量。这个向量就是该词的嵌入。
得益于 AI 的一些最新进展,我们现在可以用向量来表示单词、句子、段落,甚至整个文档。这是一个巨大的突破,因为它允许我们使用 AI 来理解文本的含义。
向量甚至可以用来表示图像、音频和视频,但在本次研讨会中,我们将专注于文本。
为什么我们需要向量?
计算机不能理解文本。它们只能理解数字。所以,我们需要一种方法将文本转换为数字。这就是向量的作用。
使用向量,我们可以在多维空间中绘制文本。很难可视化多维空间,所以让我们从二维空间开始。
想象��一个有 x 和 y 轴的图。我们的机器学习模型将在这个图上绘制各种点。这可以表示单词、句子、段落、文档,甚至是图像。
点的绘制位置由你使用的模型决定。模型将你传递的数据转换为向量。然后,它将向量绘制在图表上。
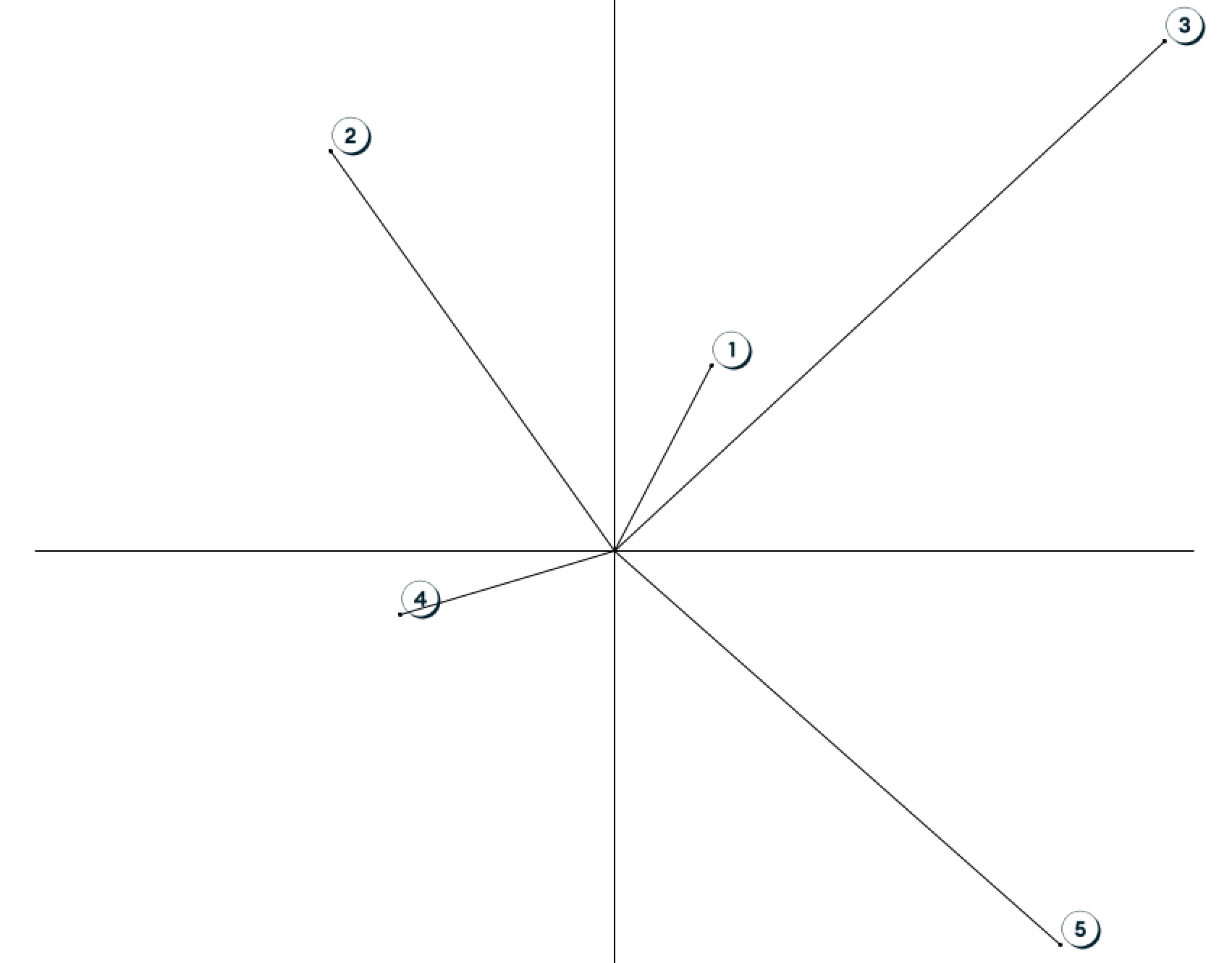
在进行搜索时,我们将为搜索词创建一个新的向量。然后我们将在图表上绘制这个新向量。
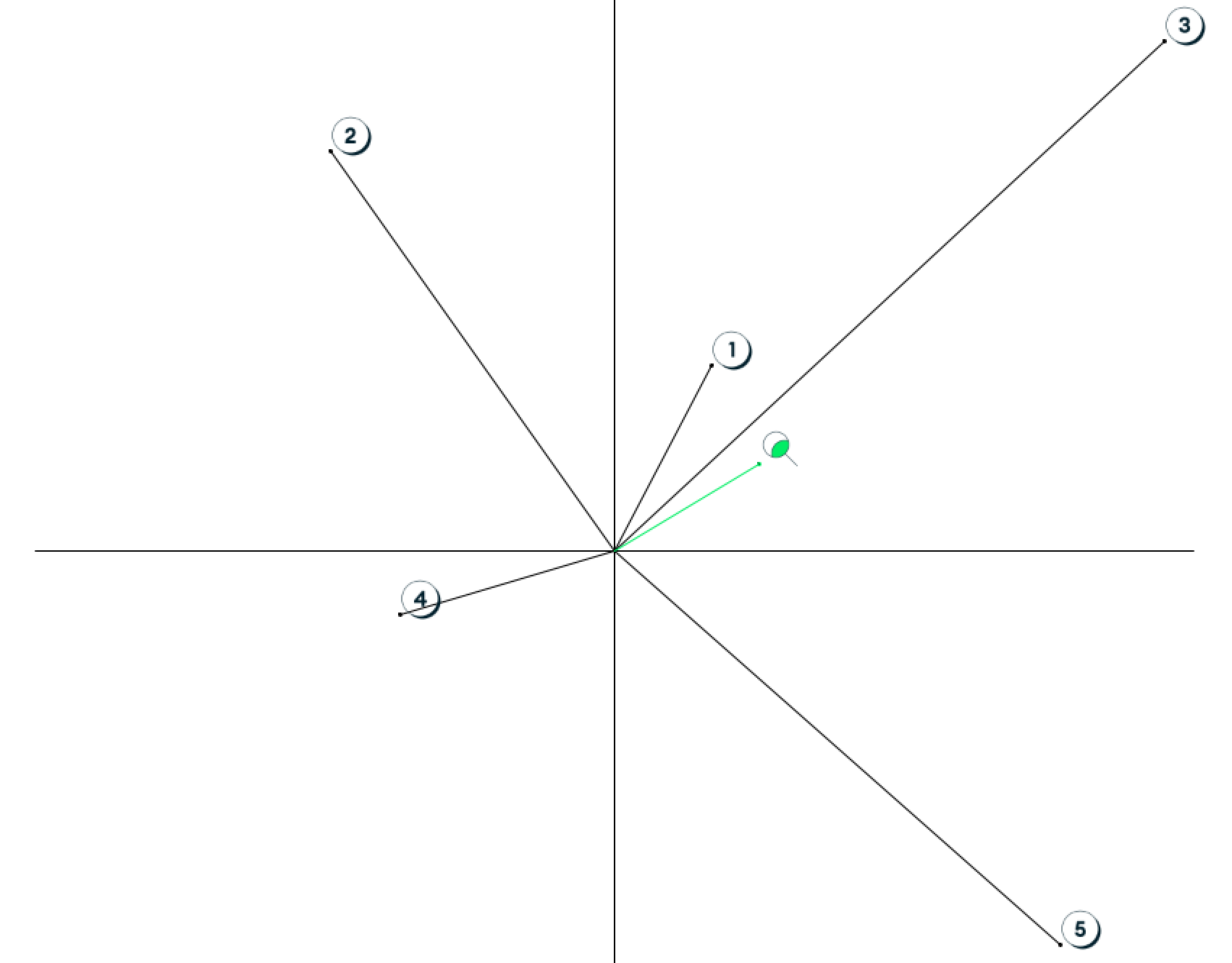
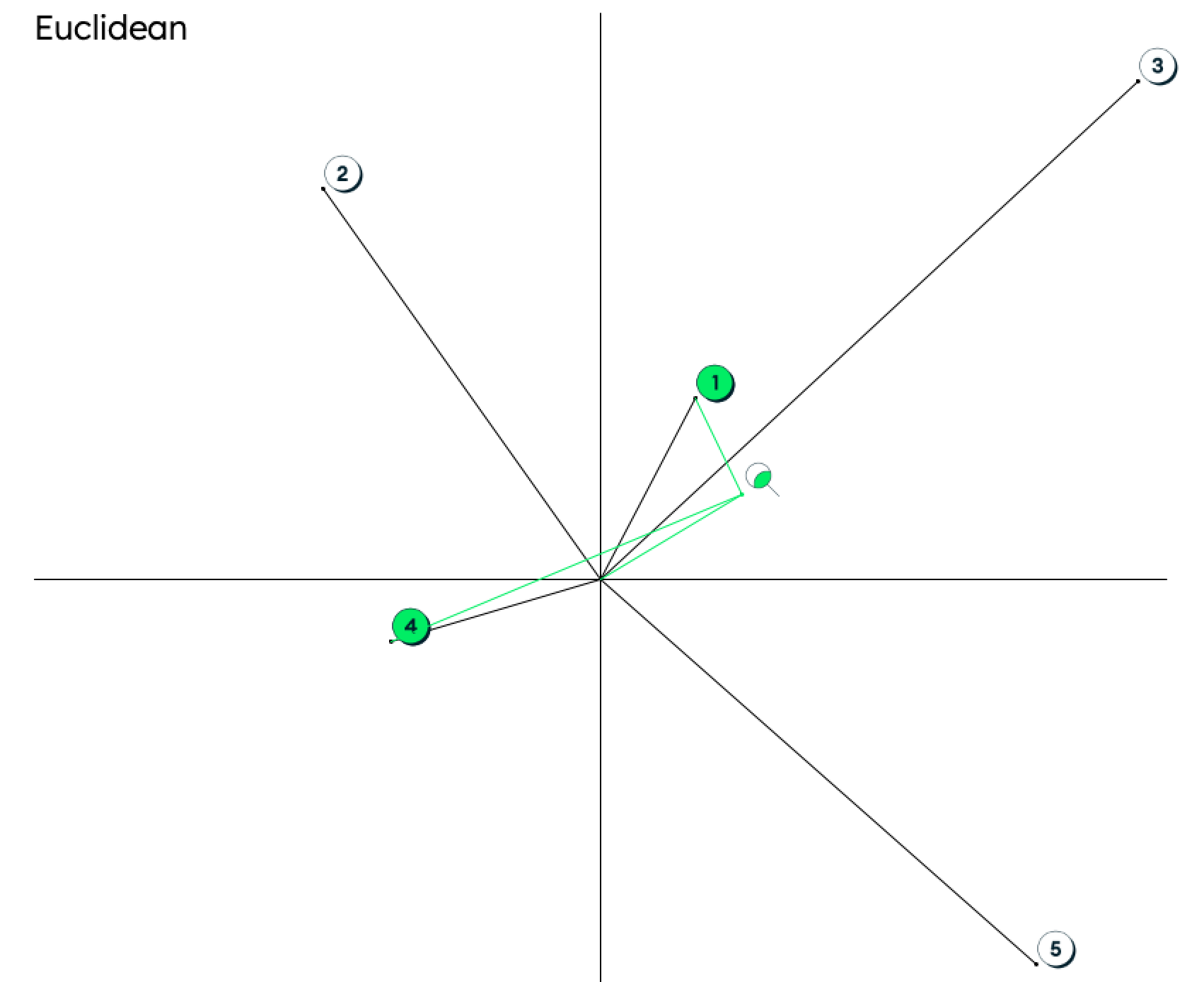
然后,我们将找到最接近搜索词的单词。最接近的单词将是那些在图表上离搜索词最近的单词。
最接近的术语将取决于你用来计算向量之间距离的算法。使用欧几里得距离,最接近的单词将是那些离搜索词最近的单词。
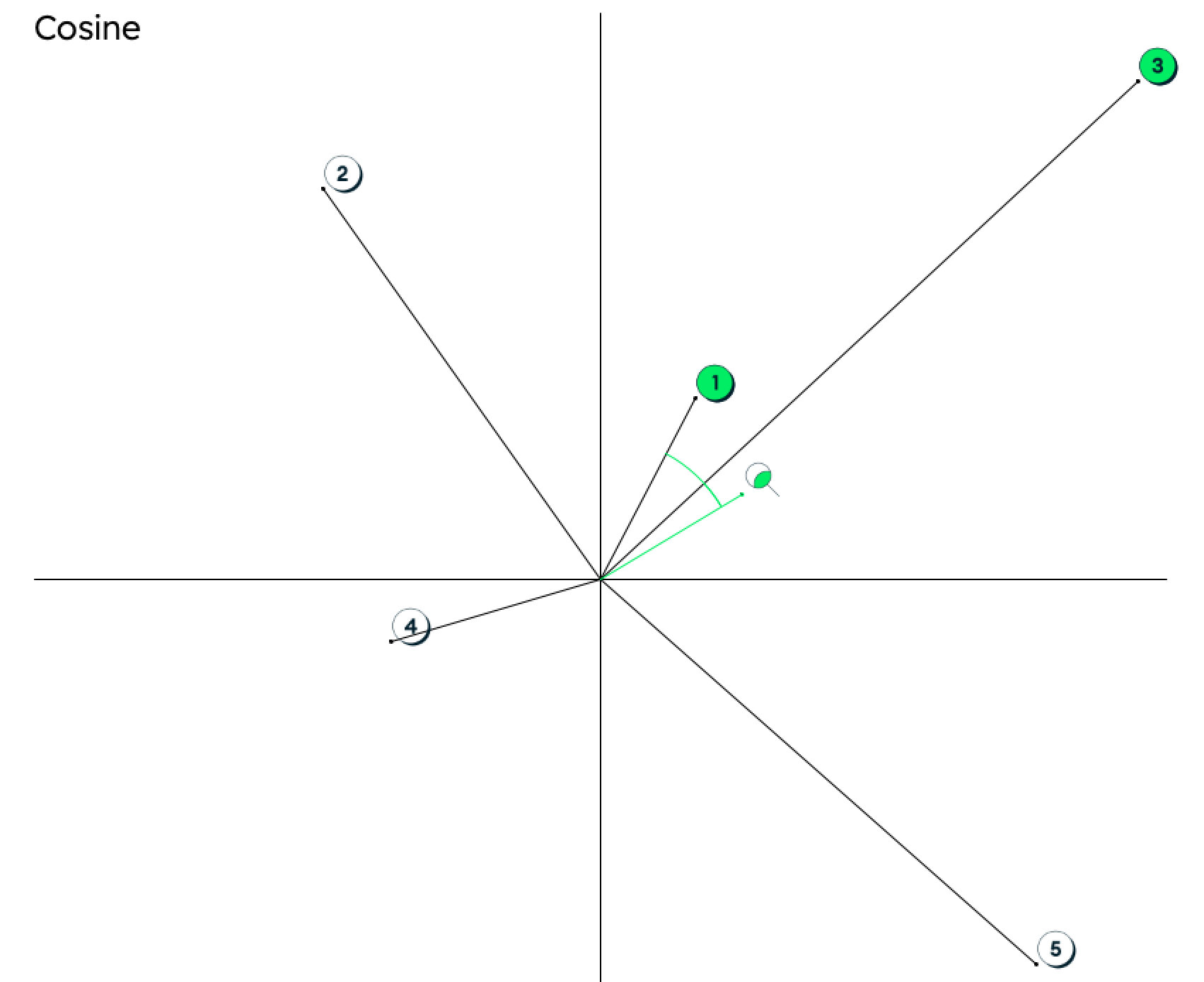
向量搜索还提供余弦算法。使用余弦距离,最接近的单词将是那些离搜索词最近,但方向相同的单词。
我们如何创建向量?
生成式 AI 的重大突破在于开发者现在可以轻松使用已经预训练并在线免费提供的模型。这些模型经过了大量数据集的训练,能够将文本(或任何类型的数据)转换为向量。
有很多方法可以创建向量。在本次研讨会中,我们将使用一个预训练模型和一个将为我们返回向量的 API。