Introducing MongoDB-RAG.com
· 3 min read

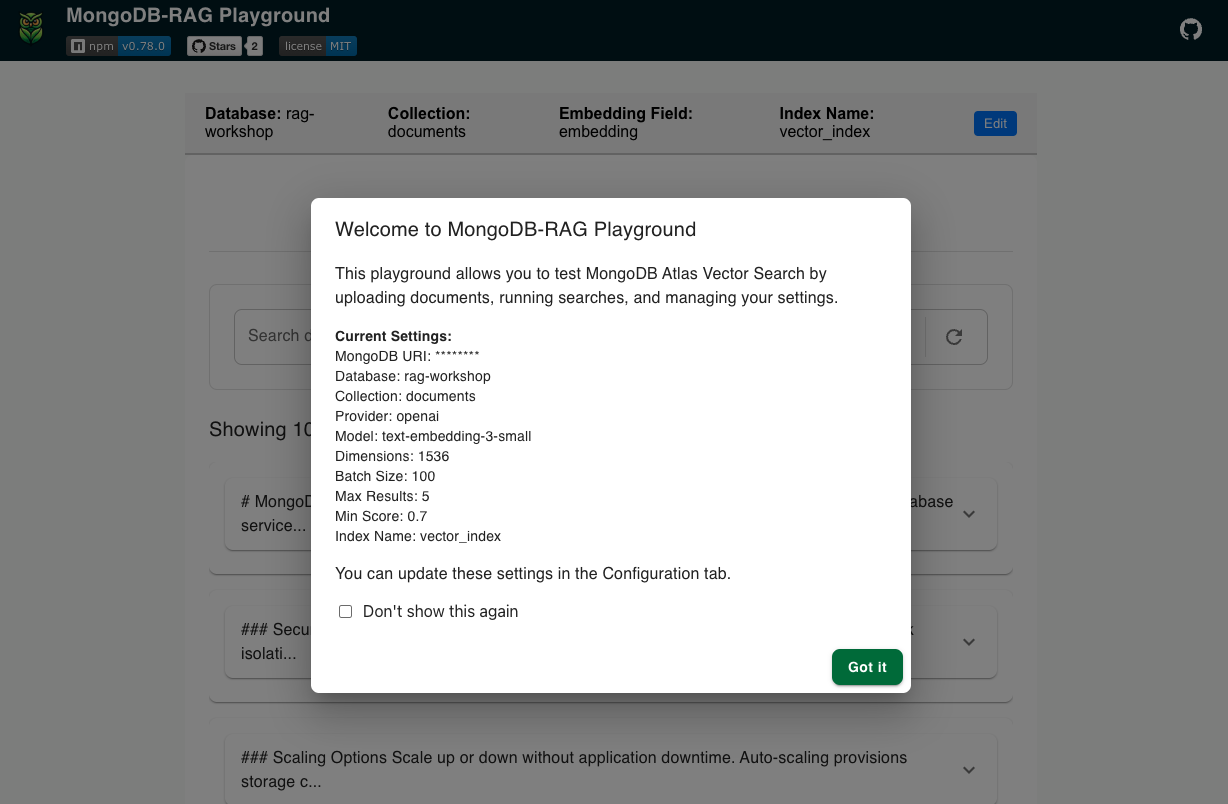
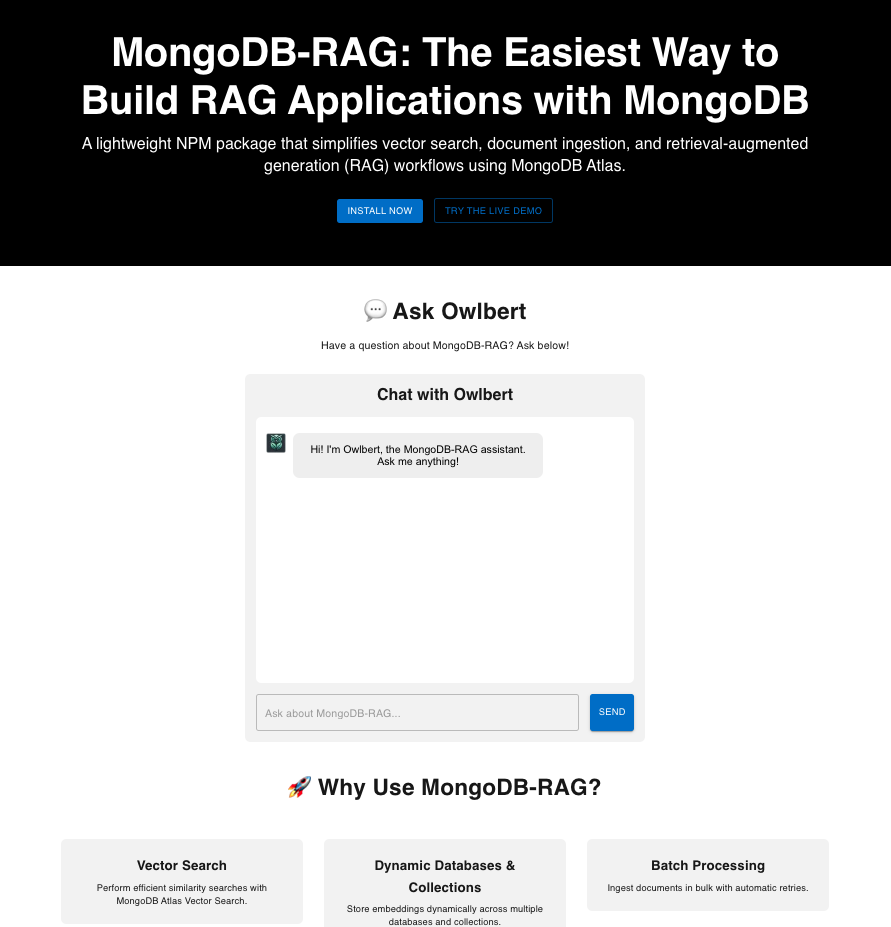
We're thrilled to announce the launch of MongoDB-RAG.com, a comprehensive marketing landing page showcasing the power and flexibility of our MongoDB-RAG npm library. This new site not only provides detailed information about the library's capabilities but also features an interactive demonstration that lets visitors experience Retrieval Augmented Generation (RAG) with MongoDB Vector Search firsthand.
What's New on MongoDB-RAG.com
The new landing page serves as a central hub for everything related to the MongoDB-RAG library, with several exciting features: