📘 How Atlas Search Works
Atlas Search uses inverted indexes to support text search queries. An inverted index is a data structure that maps each unique term in a collection to the documents that contain that term. The index is sorted by term, with each term referencing the documents that contain it.
Simple String Search
When you do a simple query in your database using a LIKE operator, or a regular expression, the database has to scan every document in the collection to find the matching documents. This is a slow process, and it gets slower as the number of documents in the collection increases.

Full Text Search
Full-text search is meant to search large amounts of text. For example, a search engine will use a full-text search to look for keywords in all the web pages that it indexed. The key to this technique is indexing.
Indexing can be done in different ways, such as batch indexing or incremental indexing. The index then acts as an extensive glossary for any matching documents. Various techniques can then be used to extract the data. Apache Lucene, the open sourced search library, uses an inversed index to find the matching items. In the case of our menu search, each word links to the matching menu item.
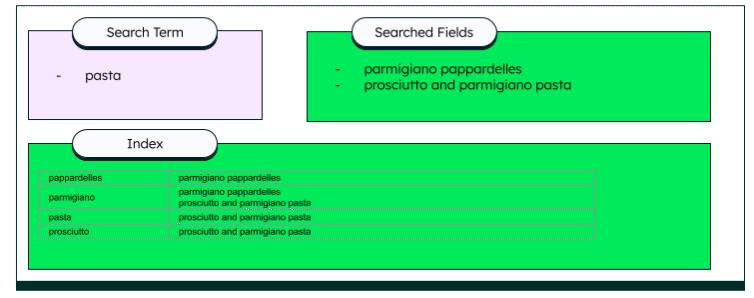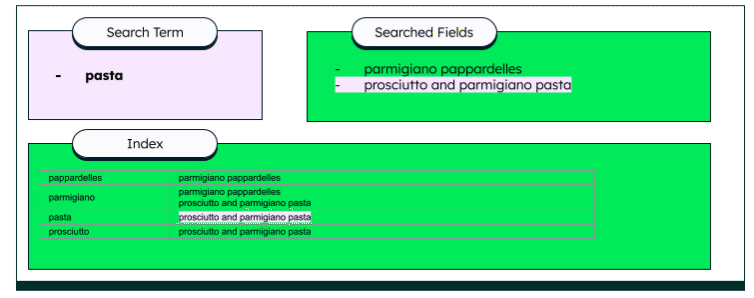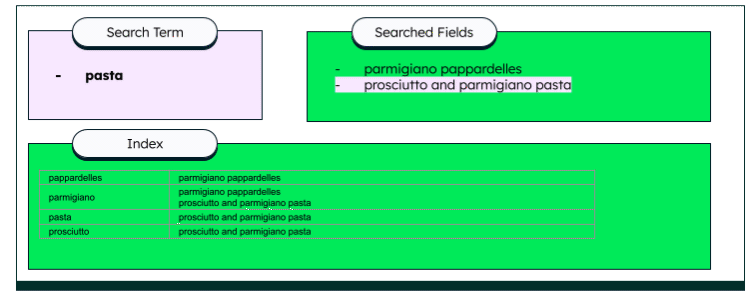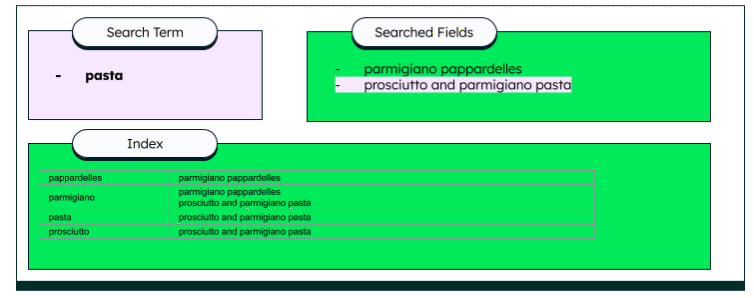
This technique is much faster than string searches for large amounts of data.
Index Creation
In order to prepare your data to be indexed, your data will go through a process called tokenization. Tokenization is the process of breaking a stream of text up into words, phrases, symbols, or other meaningful elements called tokens. This is done through a series of analyzers. Analyzers are the building blocks of the search engine. They are responsible for producing tokens out of the text. The tokens are then stored in the index.