📘 Lecture notes
There are several ways to tune and optimize your vector search queries. In this lab, we will focus on the following:
- Adding pre-filters to vector search
- Vector quantization
Adding pre-filters to vector search
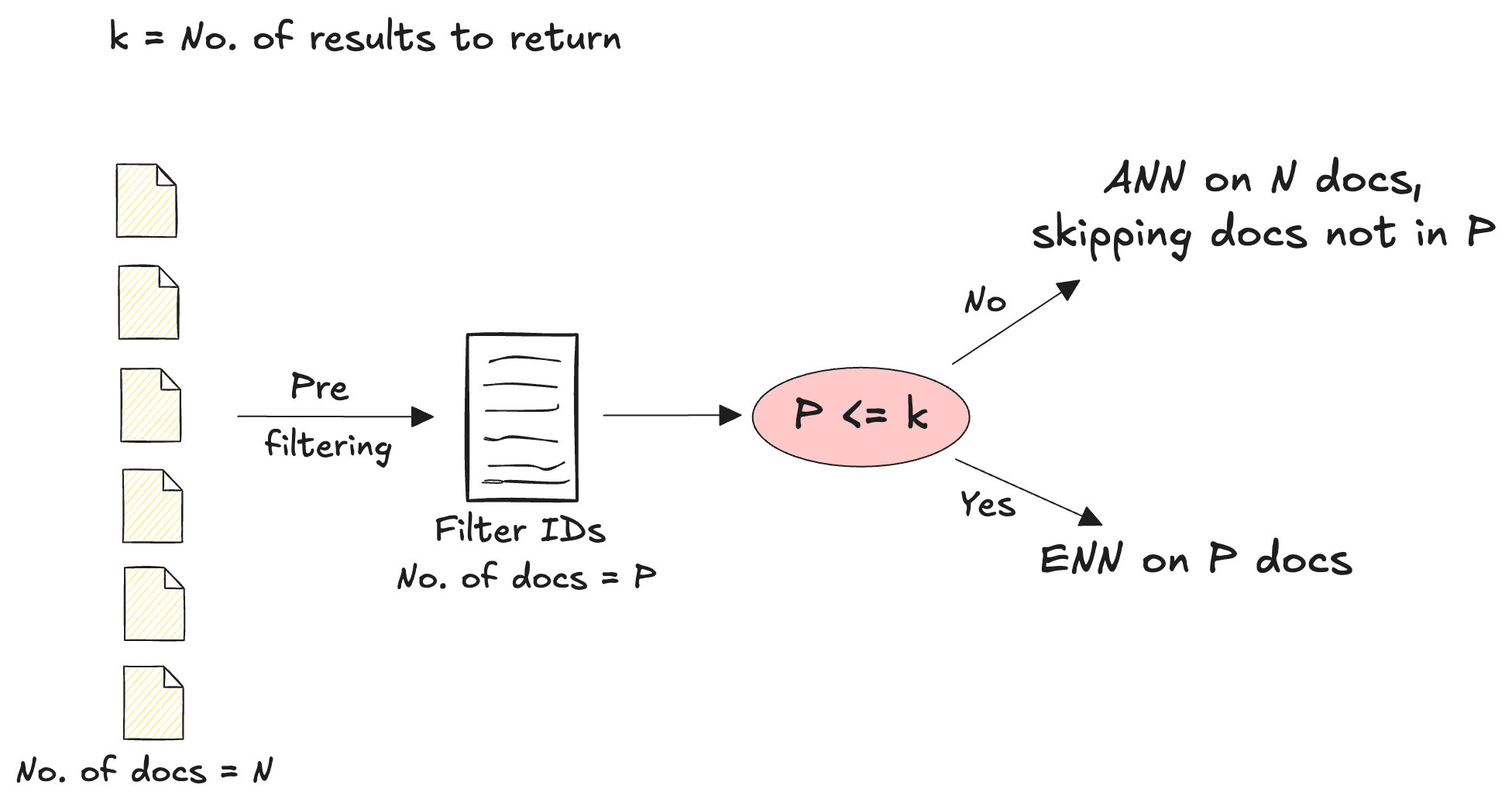
Pre-filtering allows you to filter the vector search results based on certain business logic, recency etc. In MongoDB, vector search pre-filtering works as follows:
- First, the filters are applied to your complete corpus to produce a filtered set of documents
- If the number of filtered documents is less than the number of vectors or results to be returned, an exact nearest neighbor (ENN) search is performed
- If the number of filtered documents is more than the number of documents to be returned, an approximate nearest neighbor (ANN) search is performed and when the HNSW graph is traversed, it only considers doc IDs that are present in this filtered set
This way, as long as the filters aren't too restrictive, pre-filtering can improve the latency as well as accuracy of the vector search.
To add pre-filters to vector search in MongoDB, you need to do the following:
- Update the vector search index to include the appropriate filter fields, for example:
{
"fields":[
{
"type": "vector",
"path": "embedding",
"numDimensions": 1024,
"similarity": "cosine"
},
{
"type": "filter",
"path": "pages"
},
...
]
}
- Update the
$vectorSearchstage in the aggregation pipeline definition to include the pre-filters, for example:
[
{
"$vectorSearch": {
"index": "vector_index",
"path": "embedding",
"filter": {"pages": 100},
"queryVector": [0.02421053, -0.022372592,...],
"numCandidates": 150,
"limit": 10
}
},
{
"$project": {
"_id": 0,
"Content": 1,
"score": {"$meta": "vectorSearchScore"}
}
}
]
Vector quantization
Quantization is the process of shrinking full-fidelity vectors into fewer bits. This can help reduce the storage and memory requirements for vector embeddings. MongoDB Vector Search supports two types of quantization:
scalar: Takes each vector dimension and buckets it into a smaller set of discrete integersbinary: Sets each vector dimension to a binary value based on a threshold
To enable vector auto-quantization on your embeddings, simply set the quantization field to one of the above supported quantization types in the vector search index definition, for example:
{
"fields":[
{
"type": "vector",
"path": "embedding",
"numDimensions":1024,
"similarity": "cosine",
"quantization": "scalar"
},
...
]
}
Refer to our documentation to learn more about vector quantization.