使用 Google Cloud Vertex AI
家庭作业活动,如果你在家完成,请自行进行,不会在动手实验中涵盖。
Google Cloud 现在提供了一系列基于 Vertex AI 的 AI 平台服务。这些服务旨在帮助您构建、部署和管理机器学习模型。
为了创建嵌入,他们提供了多种服务将文本、图像或两者转换为嵌入。在我们的应用中,我们将使用 multimodal 嵌入模型通过封面图像的描述搜索书籍。
创建 Google Cloud 账号
第一步是创建一个 Google Cloud 账号。使用以下链接开始并获得一些免费积分。
创建新项目
在欢迎屏幕上,创建一个新项目。你可以随意命名。
确保选择一个活跃的结算账户。
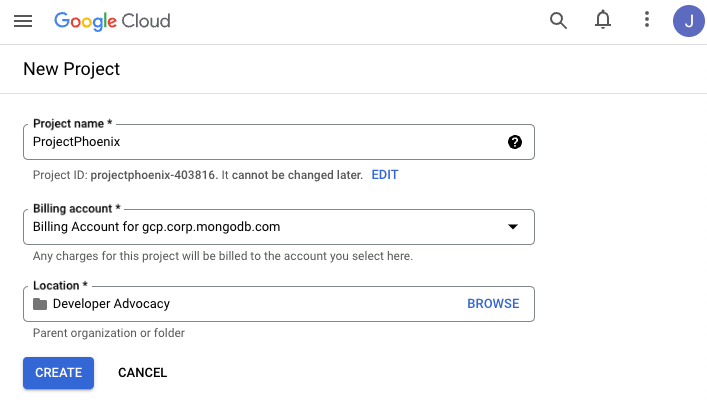
填写完字段后,点击 创建 按钮。
打开 Cloud Shell
项目创建完成后,在屏幕右上角寻找 激活 Cloud Shell 按钮。

这将在浏览器中打开一个类似终端的窗口。这是一个完全功能的终端,连接到云中的虚拟机。你可以使用这个终端在虚拟机上运行命令。
启用 AI Platform API
你需要为项目启用 AI Platform API。你可以通过在 Cloud Shell 中运行以下命令来实现。
gcloud services enable aiplatform.googleapis.com
创建认证文件
要使用 AI Platform API 进行身份验证,你需要创建一个包含应用凭据的文件。你可以通过在 Cloud Shell 中运行以下命令来实现。
gcloud auth application-default login
按照终端中的指示使用 Google Cloud 账号进行身份验证。身份验证完成后,你会看到类似以下的信息。
Credentials saved to file: [/tmp/tmp.n0HdRFDDv8/application_default_credentials.json]
将凭据文件保存到你的主目录。
mv /tmp/tmp.n0HdRFDDv8/application_default_credentials.json ~/credentials.json
创建一些文本的嵌入
为了创建一些文本的嵌入,你将首先创建一个 request.json 文件。这个文件将包含你要转换为嵌入的文本。在 Cloud Shell 中运行以下命令来创建这个文件。
echo '{
"instances": [
{
"text": "picture of a cat"
}
]
}' >> request.json
现在运行以下 curl 命令以获取文本的嵌入。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/multimodalembedding@001:predict"
确保将 $PROJECT_ID 变量更改为你的项目 ID。
你将收到类似以下的响应
{
"predictions": [
{
"textEmbedding": [
-0.00566103263,
0.0202014241,
-0.00677233562,
0.0180264488,
0.0265100803,
...
0.00116232142,
0.0134601779,
-0.00257002981
]
}
],
"deployedModelId": "5595742328217141248"
}
你会注意到 textEmbeddings 字段包含一个 1408 个数字的数组。这些是你提供的文本的嵌入。
为书籍创建嵌入
为了为你的书籍集合创建嵌入,你应该为每本书运行这个 curl 命令。这个过程有点耗时,所以我们已经为你创建好了。
你可以在导入的新书籍集合的 embeddings 字段中找到 1408 维的向量。
因为我们已经有了这些书籍的向量,我们可以使用它们进行向量搜索。
使用向量进行查询
为了查询数据,向量搜索需要计算查询向量与集合中文档向量之间的距离。
为此,你需要将查询向量化。你可以使用相同的函数来向量化你的查询。
在图书馆应用程序中,我们已经创建了一个函数来为你向量化查询。你可以在 server/embeddings/googleVertex.mjs 文件中找到它。
import aiplatform from '@google-cloud/aiplatform';
const project = process.env.PROJECT_ID;
const location = process.env.PROJECT_LOCATION;
const {PredictionServiceClient} = aiplatform.v1;
const {helpers} = aiplatform;
const predictionServiceClient = new PredictionServiceClient({
apiEndpoint: 'us-central1-aiplatform.googleapis.com'
});
const getTermEmbeddings = async (text) => {
const publisher = "google";
const model = 'multimodalembedding@001';
// 配置父资源
const endpoint = `projects/${project}/locations/${location}/publishers/${publisher}/models/${model}`;
const instance = { text };
const instanceValue = helpers.toValue(instance);
const instances = [instanceValue];
const request = {
endpoint,
instances
};
// 预测请求
const [response] = await predictionServiceClient.predict(request);
const embeddings = response.predictions[0].structValue.fields.textEmbedding.listValue.values.map(e => e.numberValue);
return embeddings;
};
export default getTermEmbeddings;
配置应用程序
在你的 server/.env 文件中,你会找到几个变量,用于配置应用程序。
第一个是 EMBEDDINGS_SOURCE。它告诉应用程序从哪里获取嵌入。你可以将其设置为 googleVertex。
然后将 EMBEDDING_KEY 设置为你的 credentials.json 文件。
最后,将 PROJECT_ID 和 PROJECT_LOCATION 设置为你的项目的值。
EMBEDDINGS_SOURCE=googleVertex
EMBEDDING_KEY="./credentials.json"
PROJECT_ID=projectphoenix-verteximage
PROJECT_LOCATION=us-central1
你的应用程序现在有一个 getTermEmbeddings 函数,它将返回给定文本的嵌入。你可以在 server/src/embeddings/googleVertex.js 文件中查看此文件的详细信息。