Construct search queries
You can construct Atlas Search queries with the $search aggregation pipeline stage.
MongoDB aggregation pipelines are multi-stage ‘assembly lines’ that reshape data and perform calculations. Pipelines can consist of one or more aggregation stages, performing different operations like match, group, sort, and output. For an exhaustive list of all available stages visit Aggregation Pipeline Stages.
In this section, we'll build an aggregation pipeline with the $search stage which performs full-text search using an Atlas Search index. The stage supports multiple operators such as:
- text
- wildcard
- near
- autocomplete
In this section, you'll use the text operator which performs textual analyzed search.
Aggregations in the Atlas UI
Navigate to the Collections tab of your database deployment.

Navigate to the Aggregation tab from the navbar under your collection details.
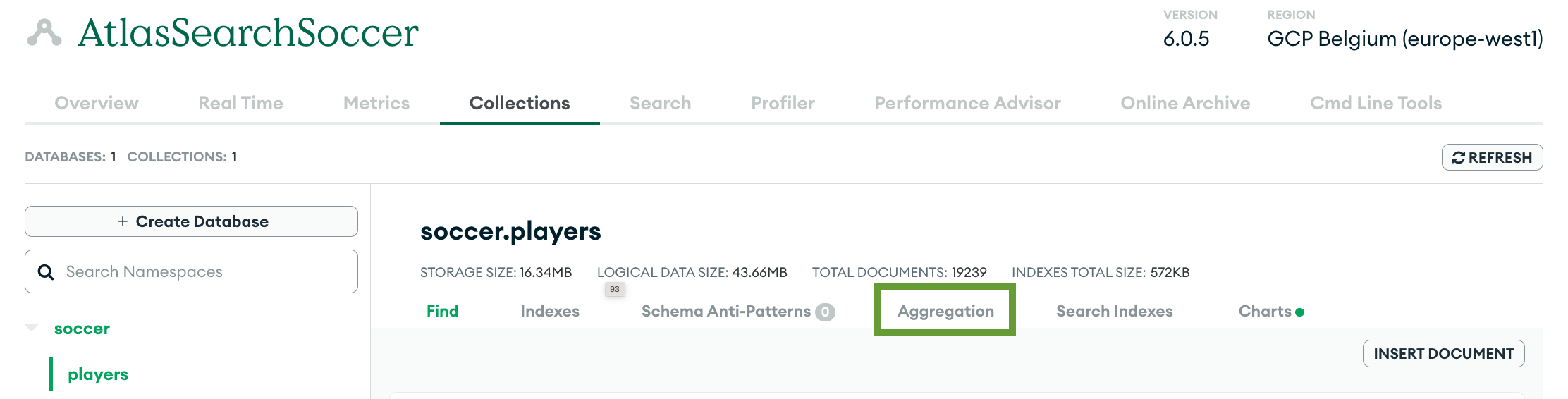
Click the first stage link.

Scroll do the Stage 1 section and type $search in the select input.
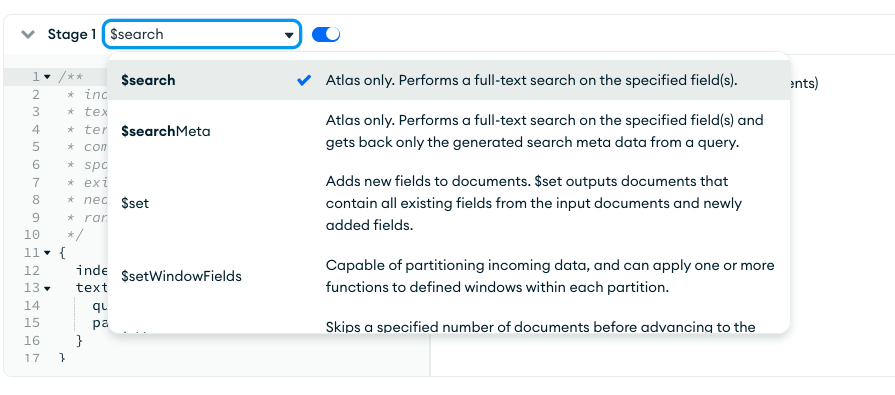
Add the following code for the
$searchstage.{
index: "default",
text: {
query: "Messi",
path: "short_name"
}
}The stage uses the "default" index. You don't need to explicitly define the index if it's "default" but you can keep it for clarity.
The
textoperator will search for “Messi” in theshort_namefield. You should see a single document returned on the right.Click the Add Stage button, scroll down, and select $project for Stage 2.
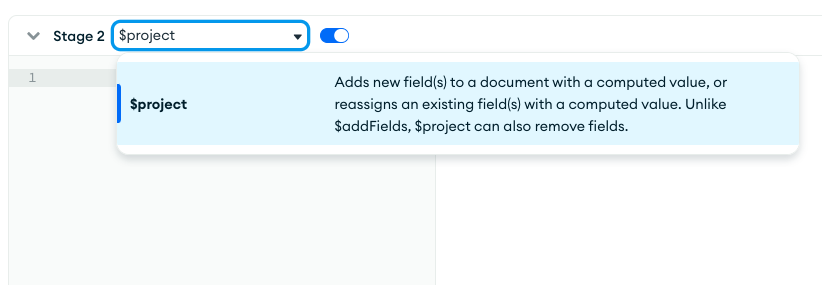
Add the following implementation for the
$projectstage to filter the returned fields.{
_id: 0,
short_name: 1,
long_name: 1,
overall: 1,
club_name: 1
}infoThis is not an exact match search but a textual analyzed search. The full text in the
short_namefield is “L. Messi”. If instead of an aggregation pipeline and$search, you usecollection.find({ short_name: "Messi" }), you won't get this document in the results.
Fuzzy matching
Next, you'll implement fuzzy matching also known as approximate string matching. Fuzzy matching helps identify two texts that are approximately similar but not exactly the same.
Try changing the query value to “Mesi”. No documents are returned. Using fuzzy matching you will be able to find the Messi document even if you misspell the name in the query.
Scroll up to Stage 1 and replace the code with the following.
{
index: "default",
text: {
query: "Mesi",
path: "short_name",
fuzzy: {
maxEdits: 1
}
}
}
You can now see that all documents with short_name similar to “Mesi” show up in the results. You can adjust the maxEdits parameter to specify how similar the returned documents can be to the query.
Document scores and modifying the search results order
In information retrieval, relevance scoring is a technique used to evaluate how closely a document matches a query. Atlas Search is built on Apache Lucene. Lucene utilizes a combination of the Vector Space Model (VSM) and the Boolean model to determine the relevance score of each search result. The VSM assesses the similarity between the query and the document, while the Boolean model determines if the document contains all the query terms. Based on these factors, Lucene assigns a score to each search result, indicating its relevance to the query.
The aggregation that we used just now returns multiple documents. Among the results are the expected Messi but also Mesa, Meli, Musi, and Mei. All of these are one character away from Mesi! To get the most popular Messi showing up first in the results, you can use the function to alter the relevance score.
You can see what's the score for each returned document by amending the $project stage.
Scroll down to Stage 2 and add the following.
{
_id: 0,
short_name: 1,
long_name: 1,
overall: 1,
club_name: 1,
score: { $meta: "searchScore" }
}On the right, you'll see the documents with the highest score first. You can also notice that the documents have the same score or a very close score. That's because all texts are 'one character away' from the query.
Scroll up to Stage 1 and add a scoring function.
{
index: "default",
text: {
query: "Mesi",
path: "short_name",
fuzzy: {
maxEdits: 1
},
score: {
function: {
add: [
{ path: 'overall' },
{ score: 'relevance' }
]
}
}
}
}You're modifying the default relevance score by using the
functionoption. The function calculates the score by adding the value of theoverallfield and the relevance score. That way, the players with the highestoverallvalues will rank first in the search results.